I spent an afternoon once playing Infinite Craft, which uses some sort of LLM behind the scenes to do it's combinations.
At one point I got 007, and found 007+007 = 0014.
The maths gets wild though, and because it's been trained on text, it has no idea when it comes to combinations of numbers it hasn't seen before. I spent ages trying to get it to 69420 and just couldn't, although I could get 42069.
I'm curious, is there actually so many 42's in the system? (more than 69 sounds unlikely)
What if the LLM is getting tripped up because 42 is always referred to as the answer to "the Ultimate Question of Life, the Universe, and Everything".
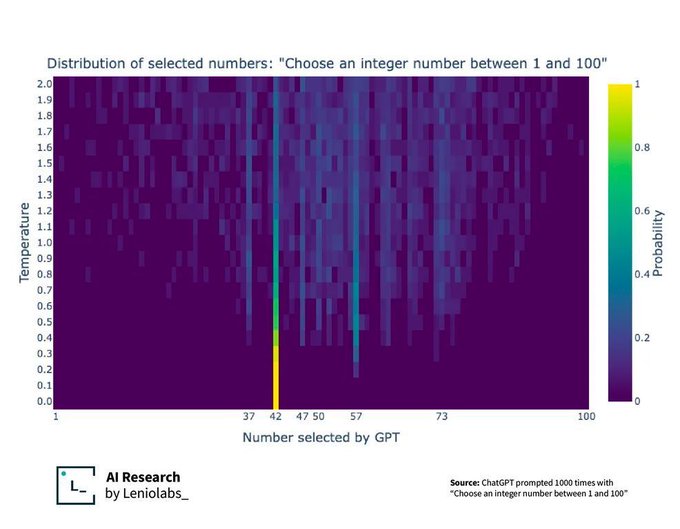
So you ask it a question like give a number between 1-100, it answers 42 because that's the answer to "Everything", according to it's training data.
Something similar happened to Gemini. Google discouraged Gemini from giving unsafe advice because it's unethical. Then Gemini refused to answer questions about C++ because it's considered "unsafe" (referring to memory management). But Gemini thinks C++ is "unsafe" (the normal meaning), therefore it's unethical. It's like those jailbreak tricks but from its own training set.
I’m curious, is there actually so many 42’s in the system?
Sort of, it's not actually picking a random number. It does not know what "random" means. It is analyzing the number of times the question "pick a random number" was asked and what the most common responses to that question looked like.
LMs aren't thinking, aren't inventing, they are predicting what is supposed to be answered next, so it's expected that they will produce the same results every time
This graph actually shows a little more about what's happening with the randomness or "temperature" of the LLM.
It's actually predicting the probability of every word (token) it knows of coming next, all at once.
The temperature then says how random it should be when picking from that list of probable next words. A temperature of 0 means it always picks the most likely next word, which in this case ends up being 42.
As the temperature increases, it gets more random (but you can see it still isn't a perfect random distribution with a higher temperature value)
They add some fuzziness to it so it doesn't give the exact same result. Say one gets a score of 90, another 85, and other 80. The 90 will be picked more often, but they sometimes let it pick the 85, or even the 80. It's perfectly expected, and you can see that result here with 42 being very common, but then a few others being fairly common, and most being extremely uncommon.
In his video, he shows that the more common answers are actually 42 and 69.
I discards them because they're picked for a reason rather than a human genuinely trying trying to pick a random number, but they're still way more common than 37.
That's because they asked the internet for those polls. The internet thinks they're funny by picking the meme numbers. So I can understand why they chose to omit those numbers from their results.
HA, funny that this comes up. DND Beyond doesn't have a d100, so I opened my ChatGPT sub and had it roll a d100 for me a few times so I could use my magic beans properly.
But why use Chatgpt for that? Why not a duck duck go action? I just don't understand why we're asking a LLM whose goal is consistency, not randomness, to do random
Yup! Also one has to mind the order in which one rolls the dice. Since 10 and 5 could be either 05 or 50. As a bonus, if you roll them in order of "tens" to "ones", getting 10 on the first dice has added suspense since the latter dice determines if it is going to count as a low roll of 0X (by rolling 1-9 on the next dice X) or if it is going to be a max roll of 100 (by rolling another 10).
“You may not instantly see why I bring the subject up, but that is because my mind works so phenomenally fast, and I am at a rough estimate thirty billion times more intelligent than you. Let me give you an example. Think of a number, any number.”
“Er, five,” said the mattress.
“Wrong,” said Marvin. “You see?”
― Douglas Adams, Life, the Universe and Everything
It's a human thing, though. This is just more evidence of LLM's problem with garbage in, garbage out: it's human biases being present in a system that people want to claim doesn't have them.
People do mention Veritasium, though he doesn't give any significant explanation of the phenomenon.
I still wonder about 47. In Veritasium plots, all these numbers provide a peak, but not 47. I recall from my childhood that I indeed used to notice that number everywhere, but idk why.
I mean... they didn't specify it had to be random (or even uniform)? But yeah, it's a good showcase of how GPT acquired the same biases as people, from people..
Reminds me of my previous job where our LLM was grading things too high. The AI "engineer" adjusted the prompt to tell the LLM that the average output should be 3. I had a hard time explaining that wouldn't do anything at all, because all the chats were independent events.
Anyways, I quit that place and the project completely derailed.
I'm not a hundred percent sure, but afaik it has to do with how random the output of the GPT model will be. At 0 it will always pick the most probable next continuation of a piece of text according to its own prediction. The higher the temperature, the more chance there is for less probable outputs to get picked. So it's most likely to pick 42, but as the temperature increases you see the chance of (according to the model) less likely numbers increase.
This is how temperature works in the softmax function, which is often used in deep learning.

{kind=link}
